Anlässlich einer netten E-Mail mit einer Einladung zu einer Veranstaltung wurde ich heute nochmals auf das Thema Tracking gestoßen. Insbesondere das Tracking, welches unbewusst und ohne Absicht erfolgt.
Das Thema liegt mir schon sehr lange neben der Tastatur, daher ist dies ein guter Anlass um es aufzugreifen.
Einführung
Heute erhielt ich Mail mit einer Einladung zum zweiten Franken Stammtisch des Bloggerclub e.V. am 21. Dezember 2017. Die Idee hinter den Bloggerclub e.V. und auch anderer ähnlicher Communities ist nichts neues: Man möchte eine gemeinsame seriöse Vertretung gegenüber Medien und Presse haben um zu zeigen, dass Blogger, also Menschen, die privat oder beruflich Artikel schreiben, durchaus was zu sagen haben. Es soll zeigen, dass Blogs nicht per se unseriös sind, sondern dass in solchen durchaus sachlich korrekte und fundierte Artikel zu finden sind; und sie sogar teilweise der Qualität von Zeitungsartikel in nichts nachstehen.
Beim Bloggerclub e.V. wird dies auch in dessen Beschreibung ausgeführt:
„Wir wollen, dass Blogs endlich erwachsen werden. Wir wollen ernst genommen werden, denn wir haben etwas zu sagen. Damit man uns aber glaubt, brauchen wir einen gemeinsamen Qualitätsstandard: den Blogger-Kodex. Er wird von allen unseren Mitgliedern eingehalten. Damit man sich auf uns verlassen kann.“
www.bloggerclub.de
Das ist auch richtig und durchaus noch angebracht. Ich selbst kenne einige Redaktionen, Lektoren, Journalisten und Redaktionsmitarbeiter, bei denen man im Gespräch anhand der Tonalität und der Wortwahl durchaus leicht erkennen kann, dass noch alte Klischees vorhanden sind.
So werden Artikel nur dann zum wertvollen Presseerzeugnis, wenn man sie über dpa oder anderen Verteilern sendet. Das hat dann auch Priorität, die dann auch starken Einfluss auf Gestaltung der Artikel hat. So werden dann auch Artikel statt mit interaktiven Links mit (nicht verlinkten) Fußnoten versehen und Bilder oder andere Medienelemente werden allenfalls als Symbolbilder für den gesamten Artikel hinzugefügt, aber niemals zu einzelnen Kapiteln.
Denselben Artikel online zu stellen, wird dann als „bloggen“ abgetan („Tu das dann halt ins Blog. Aber nichts ändern! Und erst, nachdem die Mail an den Presseverteiler raus ist!!“).
Dafür ist dann auch nach dieser klischeehaften Ansicht kein Aufwand mehr notwendig. Der ASCII-Text von dem Presseverteiler solle man nur einfach ins Web kopieren. Manche dieser potentiellen „Preisträger der Papier-Pressearbeit des vorherigen Jahrhunderts“ gehen dann sogar soweit, zu verlangen, dass der Artikel im Web auch genauso aussehen soll wie eine PM bei dpa. Wozu dann nicht nur die festgelegte Anzahl der Zeichen pro Zeile, sondern sogar der Beginn der PM mit einer Ortsangabe gehört.
Wie auch immer: Diese Klischees sind immer noch da. Und da ist es immer gut, wenn es Vereine, Verbände oder Communities gibt, die versuchen mit positiven Beispiel dagegen zu wirken.
Doch zurück zu dem eigentlichen Thema dieses Beitrags.
Der Bloggerclub e.V. hat offenbar auch das oben genannte Ziel. Zur Untermauerung hat er sich ein Codex gegeben, an welches sich jedes Mitglied des Vereins halten soll: Der Bloggerkodex. In diesem stehen verschiedene gut klingende, aber unter langjährigen Bloggern doch übliche Allgemeinplätze. Im Kodex steht unter Datenschutz:
Wir beachten die informelle Selbstbestimmung unserer Leser. Wir verpflichten uns daher, Daten nur im Rahmen der geltenden Gesetze zu erheben, zu verarbeiten und zu nutzen. Über den Umgang mit seinen Daten informieren wir den Nutzer transparent.
Die Mail wurde nicht direkt gesendet, sondern mit Hilfe einer E-Mail Marketing Software. Alle Links in der Mail waren zur Webseite des Vereins, zum Kodex oder zum Impressum waren dabei nicht direkt, sondern mit einem Tracking-Zusatz versehen, der die eigentliche Zieladresse verbarg.

Eine böse Absicht steckte nicht dahinter. Die Blogger-Kollegin, die mir die Mail schrieb, antwortete mir auf Anfrage:
Um eine einfachere Verwaltung zu haben, benutze ich den Dienst von Newsletter togo, um meine Nachrichten zu versenden.
Nur bedeutet dies jetzt trotzdem, dass meine Mailadresse und zumindest mein Vorname nun bei dem Anbieter der Software in einer Datenbank steht.
Hier wurde mit besten Absichten in die Falle getappt.
Ein schöner, gut benutzbarer Dienst im Web. Warum nicht nutzen? Was ist schon dabei?
(Unbewusstes) Tracking auf Webseiten durch Dritte
Problematischer finde ich allerdings auch die Webseite vom Bloggerclub selbst. Denn bei E-Mails kann ich selbst entscheiden, ob ich einen Link anklicke. Erst danach, nach meiner freien willentlichen Entscheidung, kann in einer Datenbank des Newsletter-Anbieters festgehalten werden, dass ich (die Links haben eine Referenz auf mein Profil), mit einem Browser vom Typ Chrome mit gewissen Plugins, zu einer Uhrzeit über eine definierte IP unterwegs war.
Bei einer Website kann ich dies nicht. Denn bereits im Moment des Aufrufs werden Daten von mir übertragen.
Wenn die Daten nur von der Webseite bzw. von dessen Webserver selbst genutzt werden, ist das auch in Ordnung. Das Internet und moderne Webangebote funktionieren nur so!
Viele moderne Webangebote nutzen jedoch inzwischen Third-Party-Bestandteile. Zum Beispiel:
- Schriften
- JavaScripten (jQuery)
- Affilate-Content
- Statistiken
- SEO-Module
- CAPTCHAs
- uvm.
Erst kürzlich brachten die Betreiber des Ghostery-Addons eine Analyse heraus (basierend auf der Stichprobe der Nutzer des AddOns, welche die Messdaten bereitstellten), wonach fast 80% aller Websites solche Third-Party-Komponenten aufweisen. Hierbei wurden allerdings nur die klassischen Tracker, wie Google Analytics oder Facebook Connect betrachtet. Schriften und Skriptlibraries wurden (noch) nicht betrachtet. Meines Erachtens gehören aber gerade diese mit dazu. Auch der Aufruf von Schriften wird bei den Servern verzeichnet. Und jeder Zugriff wird auch ausgewertet. Und, wenn möglich, natürlich auch monetarisiert.
Ghostery, uBlock Origin und andere Addons bieten mir an, alle offensichtlichen Tracker von meinen Browser abzuhalten. Nämlich indem die entsprechenden internen unsichtbaren Tracking-Links und Ressourcen nicht geladen werden oder eine Warnung auslösen.
Schriften und JavaScripten
Bei Schriften und JavaScript sieht die Sache jedoch anders aus: Wenn man hier das Laden von Google und co. unterbinden würde, könnten möglicherweise Teile der Webseite nicht mehr benutzbar sein.
Bei der Webseite vom Bloggerclub werden leider massenhaft Third-Party-Bestandteile verwendet:
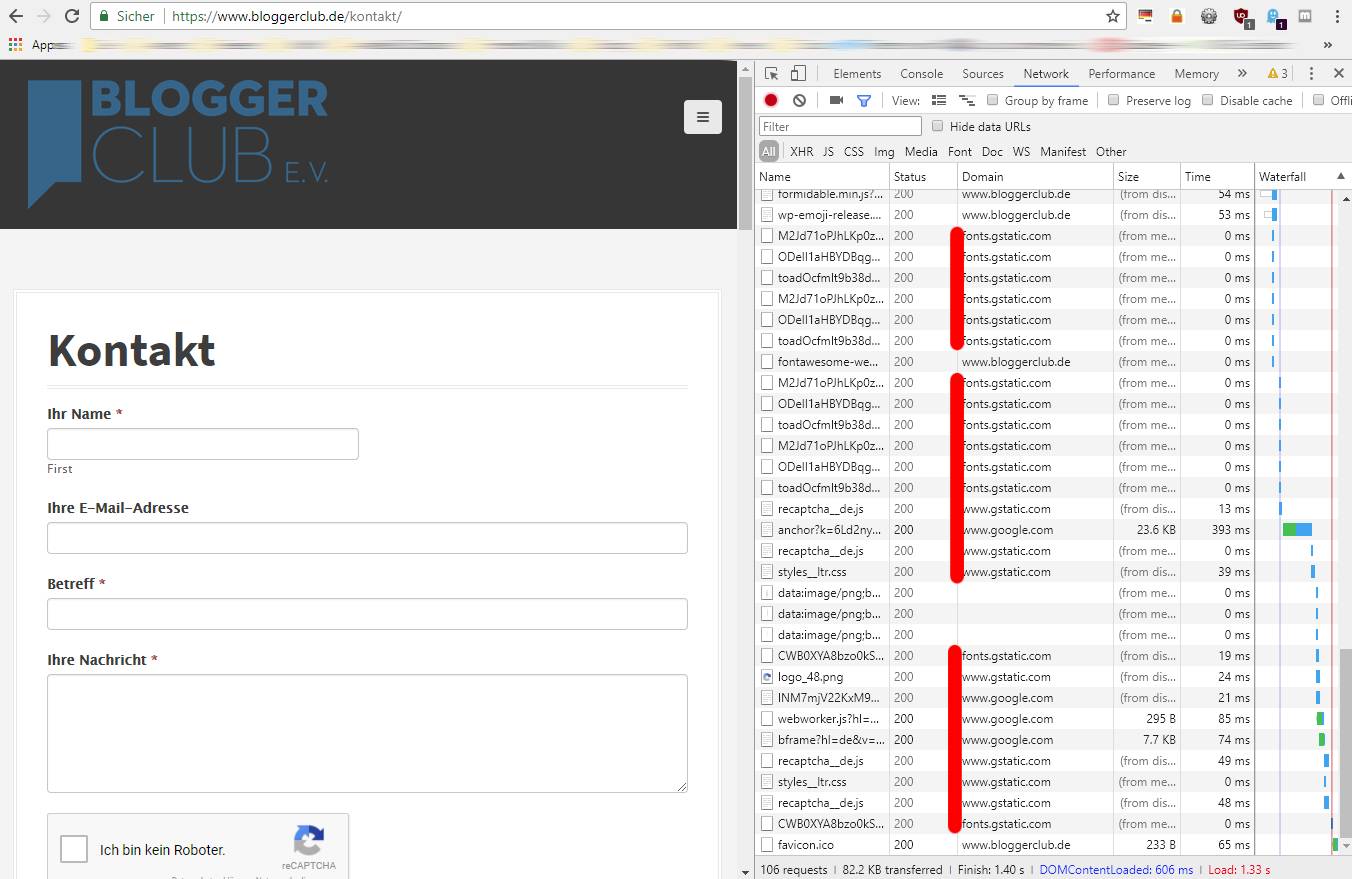
Die Schriften werden über fonts.gstatic.com geladen, verschiedene und viele JavaScripten über www.gstatic.com. Google Analytics ist zusätzlich ebenfalls dabei und die WordPress.com Statistik ebenfalls (über Jetpack). Niemand, auch der Serveradmin vom Bloggerclub nicht, kann dafür garantieren, das die JavaScripten, die vom börsennotierten und daher auch gewinnorientierten Konzern Google geladen werden, nicht doch mehr speichern als wie sie behaupten.
Dabei sieht man gerade bei dem reCAPTCHA doch, wie mächtig solche Skripten sind. Sie können nicht nur Daten der Software auslesen, die jeden von uns sehr zuverlässig über Browser-Fingerprints identifizieren lassen, sie können auch die Mausbewegungen und Tastatureingaben verfolgen.
Hand aufs Herz: Würde ich Skripten und Fonts anbieten, würde ich natürlich auch eine Statistik darüber haben und mich dafür interessieren, wer diese denn aufruft. Und ob dieser Aufruf von dem selben Nutzer nach und nach über mehrere Websites kam. Für einen neugierigen Informatiker sind solche Statistiken und Daten einfach mega-interessant. Nicht um Leute zu verfolgen, sondern einfach wegen der Möglichkeit zu sehen, was im Internet los ist. Aber leider gibt es aber nicht nur Informatiker mit akademischen Interesse, sondern auch Menschen, die in solchen Daten nur die Möglichkeit sehen, zu Geld zu kommen.
Durch die inzwischen sehr große Verbreitung der kostenlosen Schriften und der Ablage von jQuery über die CDN-Server von Google hat der Konzern die Möglichkeit quasi in Echtzeit zu analysieren, welcher Mensch welche Webseiten (sofern diese Third-Party-Komponenten oder Affilate-Links einbinden) aufruft. Er kann mitverfolgen, welche Seiten wir jetzt auf dem Browser haben und welche wir danach anklicken. Er hat sogar die Möglichkeit, mit zu verfolgen und zu speichern, welchen Daten wir in Formulare eingeben.
Google selbst schreibt zwar, dass sie keine Cookies über die Nutzung anlegen und die Privacy achten, gleichzeitig wird aber dennoch darauf hingewiesen, dass Daten bis zu einem Jahr aufgehoben und teilweise ausgewertet werden: What does using the Google Fonts API mean for the privacy of my users?
Ich schreibe daher auch nicht, dass Google tatsächlich böse Dinge tut. Ich schreibe nur, dass Google die Möglichkeiten dazu hat. Und dies gilt ja auch nicht nur für Google. Es gilt im besonderen Maße auch für Facebook. Jeder, der das interaktive Standard-Social-Media Icon von Facebook einbindet, gibt diesem im Prinzip dieselben Möglichkeiten. Natürlich gilt das auch für Twitter, für Instagram und andere.
Google hat wenigstens noch die Firmenphilosophie „Don’t be evil!“. (Wahrscheinlich ist das der Grund, warum gerade Google immer als Top-Bösewicht gehandelt wird). Doch welche Philosophie andere Firmen vertreten und tatsächlich befolgen, ist eine andere Frage. Auch YAHOO galt mal als weißer Ritter des Netzes. Inzwischen konnte man nachlesen, wie dort in den letzten Jahren mit den Daten von Menschen umgegangen wurde…
Was tun?
Zum ersten braucht es mehr an (Datenschutz-)Awareness.
Wenn wir fremden Code in unsere Webseiten einbinden, den wir nicht kontrollieren können, den wir mangels Wissen vielleicht auch gar nicht verstehen können, dann besteht immer die Gefahr, dass dieser Code auch Dinge enthält, die nicht im Einklang mit unseren Interessen und Absichten stehen. Wir „erfreuen“ uns daran, dass wir ein einfachen interaktiven Facebook-Button auf der Webseite bekommen und dafür nichts weiter dazu tun mussten, als ein Plugin zu installieren. Aber was wir daneben taten ist, dass wir all unsere Leser dem potentiellen Tracking aussetzen. Das wir für ein einfaches Buttonchen, die Daten unserer Leser opfern.
Wenn wir unsere Websites davon abhängig machen, dass vermeintliche kostenlose Skripten oder Daten von uns unbekannten Menschen oder Firmen bekommen, dann machen wir was falsch.
Um es kurz zu halten: Immer dann, wenn ich in meiner Website etwas einbinde, was Daten und Informationen von einem anderen Server läd oder dahin überträgt, Daten auswertet und eine optische Ausgabe abhängig von Daten erzeugt, dann kommt es zur oben beschriebenen Situation.
Oder um es einfach selbst zu testen:
- Man rufe die eigene Webseite im Chrome oder Firefox Browser auf.
- Klick auf Funktionstaste F12; Es öffnet sich das Entwickler-Werkzeug.
- Oben rechts klickt man auf Netzwerk bzw „Network“
- Man läd nun die Seite neu.
- In der Spalte „Domain“ sieht man alle Webauftritte von denen Daten geladen werden. Wenn nur der eigene Webauftritt dabei steht, ist alles gut. Wenn dort Domains wie facebook.com, twitter.com, gstatic.com oder andere stehen, dann hat man einen Tracker auf der eigenen Webseite.
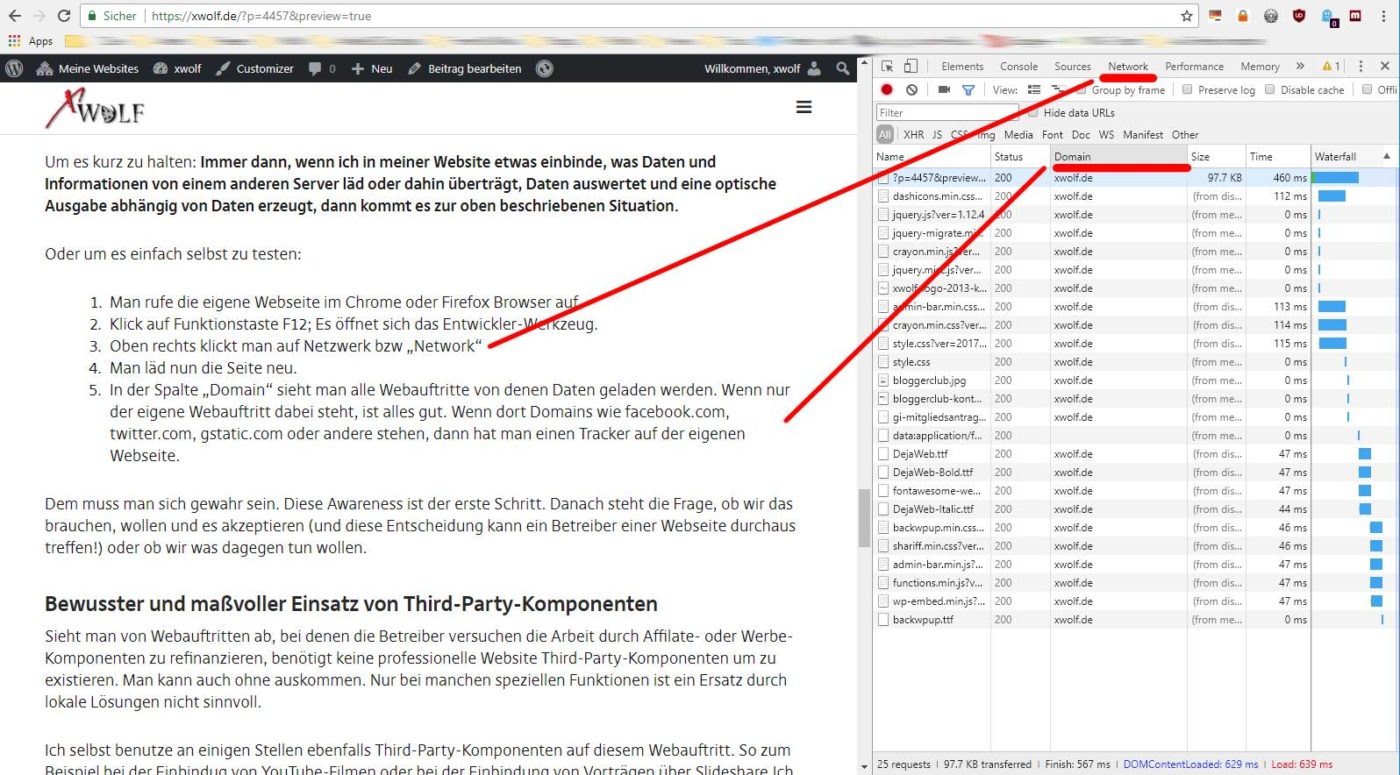
Dem muss man sich gewahr sein. Diese Awareness ist der erste Schritt. Danach steht die Frage, ob wir das brauchen, wollen und es akzeptieren (und diese Entscheidung kann ein Betreiber einer Webseite durchaus treffen!) oder ob wir was dagegen tun wollen.
Bewusster und maßvoller Einsatz von Third-Party-Komponenten
Sieht man von Webauftritten ab, bei denen die Betreiber versuchen die Arbeit durch Affilate- oder Werbe-Komponenten zu refinanzieren, benötigt keine professionelle Website Third-Party-Komponenten um zu existieren. Man kann auch ohne auskommen. Nur bei manchen speziellen Funktionen ist ein Ersatz durch lokale Lösungen nicht sinnvoll.
Ich selbst benutze an einigen Stellen ebenfalls Third-Party-Komponenten auf diesem Webauftritt. So zum Beispiel bei der Einbindung von YouTube-Filmen oder bei der Einbindung von Vorträgen über Slideshare. Ich könnte die YouTube-Videos oder die Vorträge auch verlinken anstelle sie einzubinden. In dem Fall hab ich mich für die betreffenden Seiten (und nur für die) aber bewusst dafür entschieden, es doch so zu tun, weil der Vorteil der Usability dort höher ist als der Nachteil des Trackings durch die Einbindung.
Fonts
Alle Fonts, die bei Google zur Verfügung gestellt werden, können auch heruntergeladen und lokal auf den eigenen Webserver abgelegt werden. Jeder Webdesigner und Webentwickler, der die Grundlagen von CSS beherrscht, sollte in der Lage sein, dies auch in seine Themes oder Webdesigns umzusetzen. Geschieht dies nicht, ist der Webdesigner an der Stelle zu faul, um den Font von Google zu laden und im CSS 3 Zeilen zu ändern, dann sollte man sich zweimal überlegen, ob man das Theme wirklich will. Wenn man dafür noch Geld bezahlt hat, weil es eine Auftragsarbeit war, würde ich dies als Mangel reklamieren.
JavaScripten
JavaScripten und hierzu gehört insbesondere die jQuery Bibliothek, können ebenso wie Schriften auf den eigenen Server abgelegt werden. Das ist sogar noch einfacher als die Schriften, da hierfür lediglich die URL zum Skript geändert werden muss.
Social Media Icons
Das Social Media Icons zum Abschöpfen von Daten verwendet werden, ist seit langen Jahren bekannt. Das Wissen ist sogar schon so verbreitet, dass selbst behördliche Datenschutzbeauftragte darauf hinwiesen. Trotzdem möchte man die „Teilen“-Funktion nicht entfernen. Die Lösung hierzu sind Skripten wie Shariff. Shariff gibt es für WordPress aber auch für andere CMS und für „handmade“-Websites.
Niemals Third-Party-Komponenten auf Login- oder Registrierungsseiten einsetzen!
Egal, ob man auf den normalen Seiten eines Webauftritts Third-Party-Komponenten bewusst zulassen will oder nicht, an zwei Orten sind sie dennoch tabu:
- Auf Webseiten zum Login für einen internen Bereich Benutzernamen und Passworte eingegeben werden.
- Auf Webseiten, wo sich neue Benutzer registrieren und dazu vertrauliche Daten eingeben müssen.
Auf solchen Seiten wird auch keine Social Media oder YouTube Einbindung benötigt, wie dieses Beispiel einer Webseite zeigt, von der man aufgrund der Zielgruppe eigentlich hätte annehmen können, dass sie diesen Fehler nicht nur nicht macht, sondern ihn auch behebt, nachdem auf die Problemlage hingewiesen wurde.
![]()
Der Hacker vom heute sitzt nicht in einem dunklen Zimmer mit dem Hoodie vor einem Computer.
Er liegt mit einem Coctail in der Hand unter karibischer Sonne und lebt davon die Daten von uns und unseren Lesern, die wir ihm für ein lustiges Bildchen überließen, zu analysieren und zu kategorisieren und an andere zu verscherbeln.
Nein, „Don’t be evil“ hat Google bereits mit großem Pressewirbel als Fehler bezeichnet.
Ist halt informelle Selbstbestimmung, keine informationelle.
Danke dir.. Ich lese deine Artikel immer mit großem Interesse